What is a VLA Model? How Vision-Language-Action Powers Embodied AI
The robotics industry is undergoing a historic paradigm shift [1]. For decades, programming a robot meant writing thousands of lines of deterministic code or training narrow reinforcement learning policies in highly controlled simulations [1]. If a cup was moved two inches to the left, or the lighting in a room changed, the robot would fail.
Today, that rigid era is ending. The rise of Embodied AI—intelligence grounded in physical agents—has introduced a revolutionary architecture: the VLA (Vision-Language-Action) model [2][3].
But what exactly is a VLA model, and how is it transforming how robots interact with our world? More importantly, how are researchers solving the massive data bottleneck required to train these physical brains? Let’s dive in.
What is a VLA Model in Robotics?
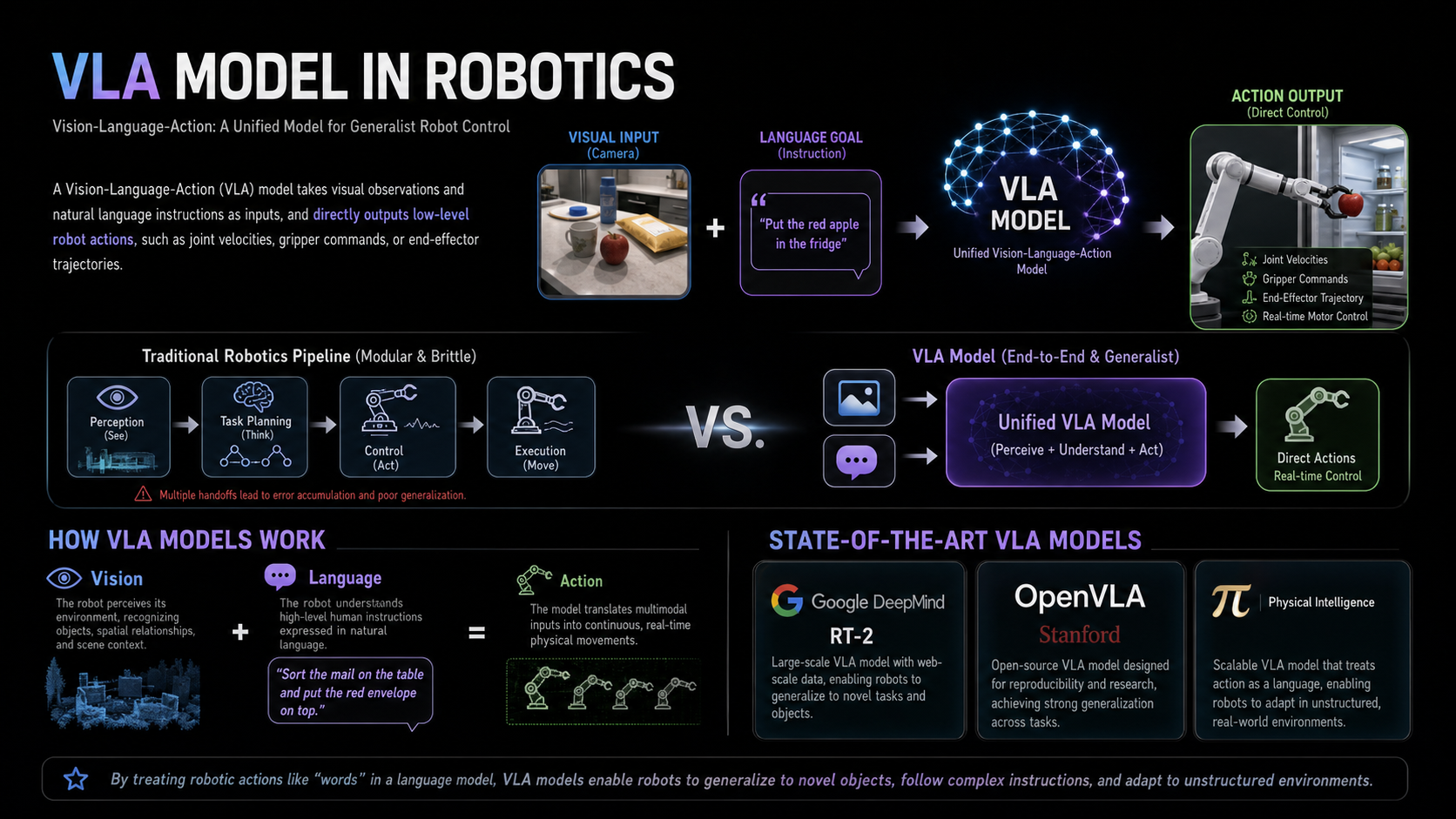
A Vision-Language-Action (VLA) model is a unified neural network that takes visual observations (images or video) and natural language instructions as inputs, and directly outputs low-level robot actions (such as joint velocities, gripper commands, or end-effector trajectories) [2].
Unlike traditional robotics pipelines that split perception, task planning, and control into separate, brittle modules, a VLA model handles everything end-to-end [2][4].
- Vision: The robot perceives its environment (e.g., recognizing a messy kitchen counter) [5].
- Language: The robot understands a high-level human command (e.g., “Put the red apple in the fridge”) [4].
- Action: The model translates these multimodal inputs into continuous, real-time physical movements [5].
SOTA models like Google DeepMind’s RT-2, Stanford’s OpenVLA, and Physical Intelligence’s
π0 have proven that by treating robotic actions like “words” in a language model, robots can generalize to novel objects, follow complex instructions, and adapt to unstructured environments [2][6].
How Do We Train VLA Models? The Data Bottleneck
While VLA models are incredibly powerful, they are notoriously data-hungry [7]. To teach a robot how to fold a shirt, sort a package, or open a microwave, the model must learn from thousands of high-quality demonstrations [7].
This training paradigm is called Imitation Learning (or Behavior Cloning) [6][7]. By watching how humans perform tasks, the AI learns the mapping between visual changes in the environment and the corresponding physical actions [7][8].
However, traditional data collection methods pose major hurdles:
- Teleoperation is slow: Maneuvering a robot arm via VR controllers or joysticks is tedious and unnatural [7].
- Third-person cameras miss details: Static cameras mounted on a wall or tripod often suffer from occlusions (e.g., a hand blocking the camera’s view of an object).
- Lack of spatial depth: Standard 2D video feeds do not capture the precise 3D spatial coordinates required for dexterous manipulation.
To build robust datasets, researchers are shifting toward Egocentric (First-Person) Video Data Collection [5]. By capturing data directly from the human operator’s point of view, AI models can learn natural, hand-eye-coordinated workflows [5][7].
Introducing Virdyn VDEgo-C2: The Ultimate FPV Head-Mounted Camera for VLA Data Collection
To bridge the gap between human demonstration and robotic action, Virdyn has engineered the VDEgo-C2, a professional binocular egocentric FPV head-mounted camera designed specifically for Embodied AI and VLA model training.
The VDEgo-C2 acts as a high-fidelity sensory bridge, allowing researchers to effortlessly record natural human workflows across diverse, real-world tasks.
Why VDEgo-C2 is a Game-Changer for Embodied AI Researchers:
- True Binocular Stereo Vision (First-Person Perspective):
Featuring a dual-camera setup, the VDEgo-C2 captures depth and spatial relationships exactly as a human does. This eliminates the “occlusion problem” of static cameras, ensuring the AI model sees exactly how fingers interact with objects. - High-Frequency IMU Synchronization:
The camera integrates high-precision Inertial Measurement Units (IMU) synchronized with the video frames. This provides critical head-motion and orientation data, helping VLA models learn spatial reasoning and visual attention mapping. - Seamless Multi-Scene Data Collection:
Whether your research focuses on smart home assistants or industrial automation, the lightweight, ergonomic head-mounted design allows operators to collect data naturally across countless scenarios, including:Developer-Friendly Multimodal Outputs:- Household Chores: Folding and organizing clothes, organizing refrigerators, or heating food in a microwave.
- Logistics & Warehousing: Sorting parcels, picking items, and handling packaging.
- Precision Tasks: Operating printers, using tools, and fine-grained assembly.
- VDEgo-C2 outputs neatly organized, timestamped data packages (including H.265 video and IMU logs) that are ready to be ingested directly into machine learning pipelines like PyTorch, LeRobot, or custom VLA training loops [2].

How to Get Started with VLA and VDEgo-C2
Building a general-purpose robotic brain requires high-quality, diverse, and out-of-distribution real-world data [5]. By equipping human operators with the Virdyn VDEgo-C2 FPV Head-Mounted Camera, your research team can scale up egocentric video data collection by 10x, compiling rich datasets of daily human-object interactions [5].
With the right hardware capturing the data, and VLA models executing the actions, the dream of truly intelligent, adaptable humanoid robots is closer than ever [1].
Ready to supercharge your Embodied AI data pipeline? [Visit Virdyn’s Official Website] to learn more about the VDEgo-C2 and pre-order your developer kit today!
Learn more:
- Vision-Language-Action Models: The New Frontier in Embodied AI – RobotWale
- VLA Models in Robotics 2026: RT-2 vs OpenVLA vs π0 vs MolmoAct 2 – RoboCloud Hub
- Vision-Language-Action Foundation Models for General Embodied Intelligence
- Vision-Language-Action (VLA) Models: LLMs for robots | by Gaurav Gupta – Medium
- Qwen-VLA: From Understanding the World to Acting in It
- Best VLA Models 2026: Complete Guide | Robotics Center of Silicon Valley
- Foundation Models for Robotics: Vision-Language-Action (VLA) | Rohit Bandaru
- Pretrained to Imagine, Fine-Tuned to Act: The Rise of World-Action Models